



| Technical Name | Lightweight End-to-End Deep Learning Model for Music Source Separation | ||
|---|---|---|---|
| Project Operator | National Central University | ||
| Project Host | 王家慶 | ||
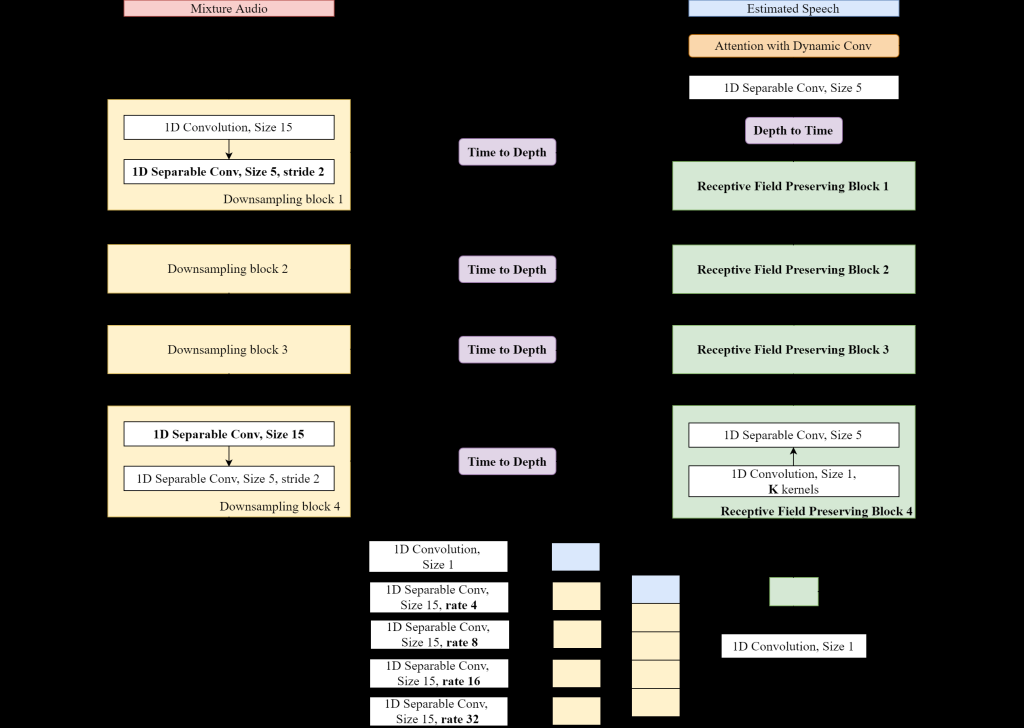
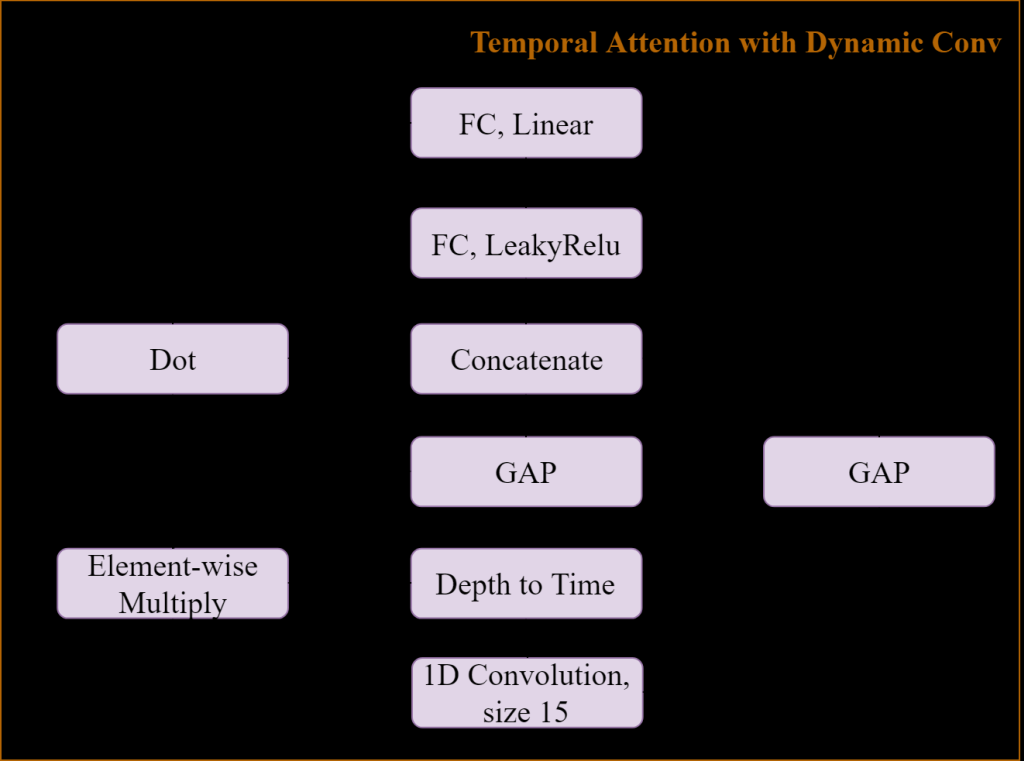
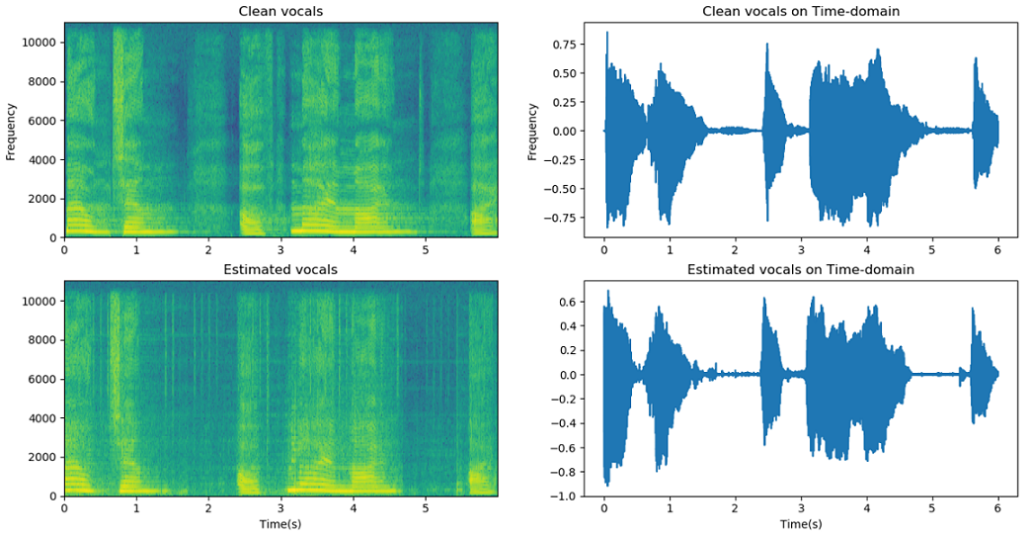
| Summary | The proposed method, an end-to-end lightweight music source separation based on deep learning model using time domain information. The complexity of the modelthe computing time are both reduced by introducing Atrous Spatial Pyramid Pooling. The Temporal Attention with Dynamic Convolution Kernelthe Receptive Field Preserving Decoder are proposed to enhance the performance of music source |
||
| Scientific Breakthrough | The proposed single channel end-to-end music source separation model works with image semantic segmentation skills which reducing layer number in network. The proposed model now with only 10 of number of parameters of previously proposed modelsshows even better result. The proposed "Depth to Time" also reduced calculationmakes running real-time application on resource limited |
||
| Industrial Applicability | The previously proposed sound source separation models are already claimed with good enough result. However, those models are with high complexityhuge amount of parameters. These models are note suitable for running real-time application on devices with limited resource. Though the proposed method aimed music sourcehuman voice separation, this can be extended to other real-time applicati |
||
| Keyword | Music Source Separation Wave-U-Net Atrous Spatial Pyramid Pooling Atrous convolution Encoder-decoder Temporal Attention Dynamic convolution kernel Receptive Field Preserving Decoder Semantic Segmentation Depthwise Separable Convolution | ||
- holidaypanic@hotmail.com
other people also saw