| 技術簡介 |
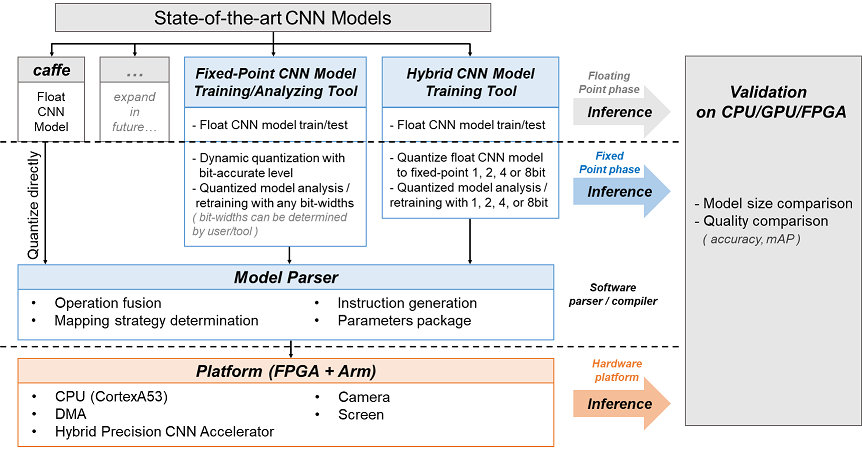
本作品設計了Hybrid CNN硬體加速器系統與其深度學習模型訓練分析工具
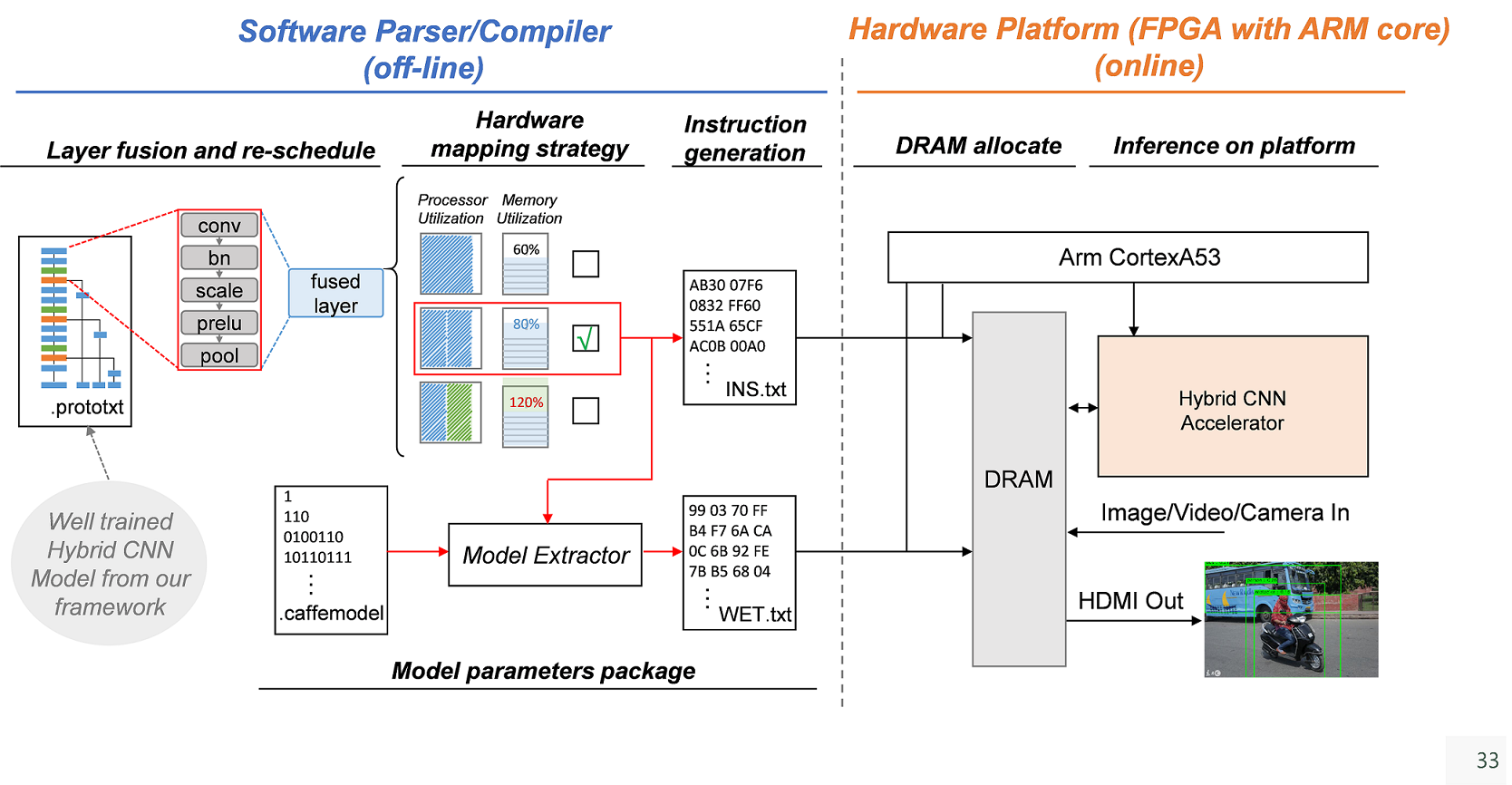
Hybrid CNN硬體加速器系統
1. 採用SPE高效率的處理混和精度模型運算,可支援1, 2, 4 ,8bit的CNN運算,並且可以動態切換不同的輸入位元運算模式,讓混和精度硬體加速器的計算單元持續處於在高使用率的狀態。
2. 透過Input Ping-Pong Buffer來優化DRAM資料存取以及混和精度硬體加速器運算的程序排程;採用2-Stage Input Buffer來減少2-D Systolic PE Array在傳送資料時的時脈延遲,讓Hybrid CNN加速器之硬體使用率更進一步提升。
3. 透過獨立的Partial Sum Sorter來存取On-chip Memory,使Hybrid CNN硬體加速器在各種模式下都可以讓On Chip Memory維持在100%的使用率。
4. 混和精度硬體加速器支援採用動態定點數量化過的CNN模型,輸出資料可以量化成1, 2, 4 or 8bit,相較於採用INT16/32作為輸出的硬體加速器,其輸出頻寬需求大幅度的降低。
5. 具備與Hybrid CNN硬體加速器對應之完整的CNN Model Parser/Compiler,目前支援BVLC caffe與我們開發的訓練分析工具(IVS-Caffe),預計未來會持續增加所支援的深度學習訓練framework架構。
深度學習模型訓練分析工具
1. 透過Knowledge Transfer、Dynamic Quantization等方法,此工具可以訓練出大幅度簡化的Hybrid CNN模型。
2. 使用SSTE的方式來解決Bit accurate level的CNN模型在訓練時所產生的偏微分回傳問題,透過統計乘法器以及加法器的Overflow頻率,並讓Overflow頻率較高的位置不進行偏微分回傳,以減少因為STE產生的偏微分誤差。
3. 本團隊開發了一個自動深度學習模型架構定點數量化/訓練工具(ezQUANT),可以自動量化深度學習浮點數模型,成為動態定點數模型並進行重新訓練。使用者只需要提供浮點數模型、訓練、校正、測試資料、還有可以接受的準確度下降量等,即可透過此工具自動產生量化後之深度學習模型定點數模型架構,即可移植於前述混和精度硬體加速器上實現。 |