



| 技術名稱 | 端到端輕量化音樂源分離深度學習模型 | ||
|---|---|---|---|
| 計畫單位 | 國立中央大學 | ||
| 計畫主持人 | 王家慶 | ||
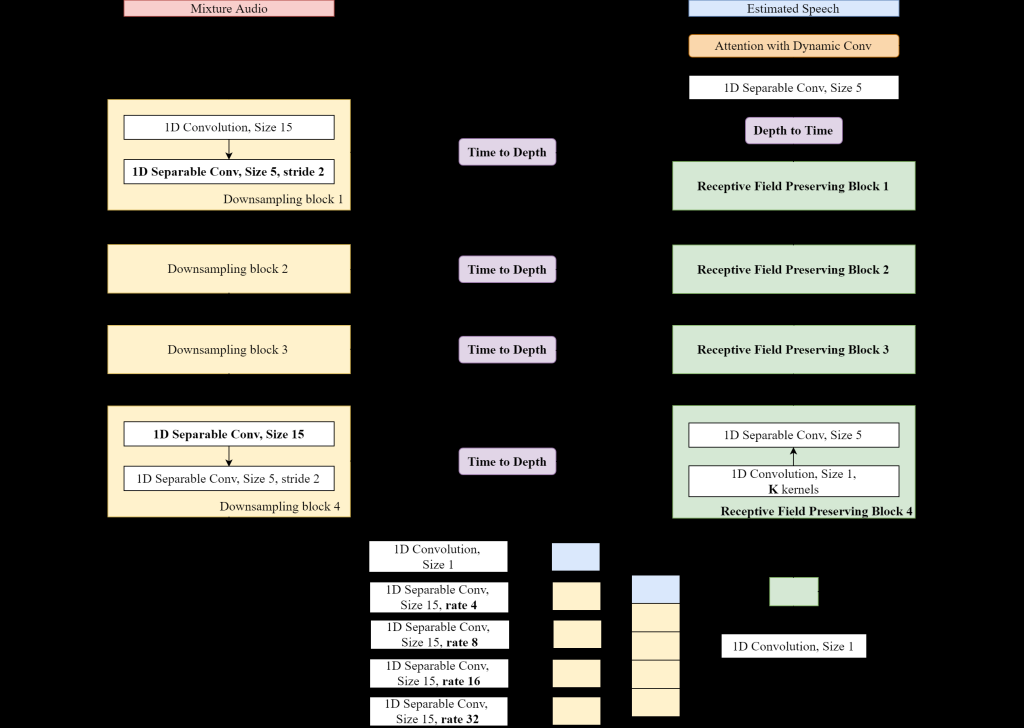
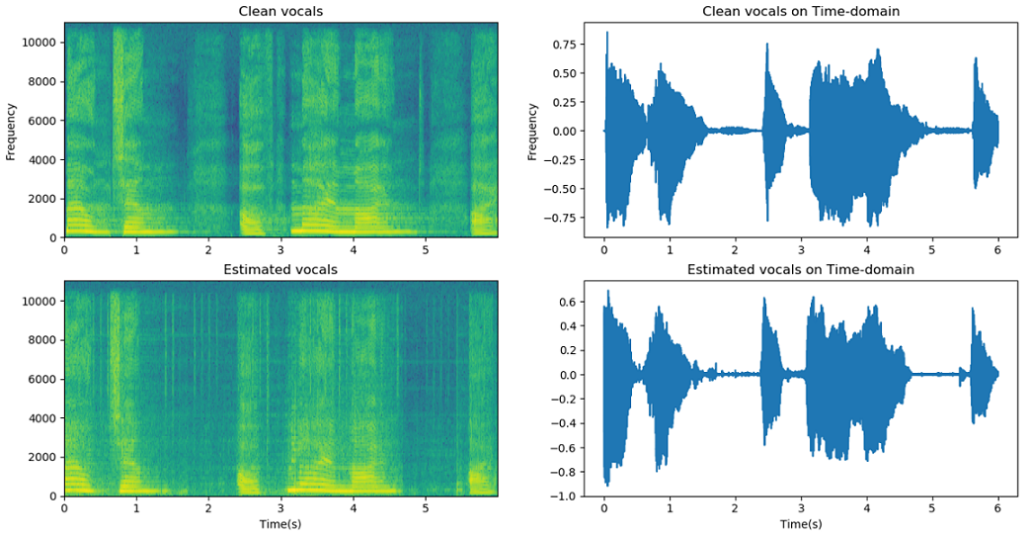
| 技術簡介 | 本技術提出了基於時域資訊直接進行端到端輕量化音樂源分離深度學習模型,運用空洞空間卷積池化減少模型參數量並加速運算,並加入基於時間注意力機制的動態卷積核,以及提出接受域不變之解碼器進一步提升在輸入時間長度受限的狀態下的分離效果。實驗結果表明,只需過去10以下或是更少的參數量即可獲得優於之前的分離結果 |
||
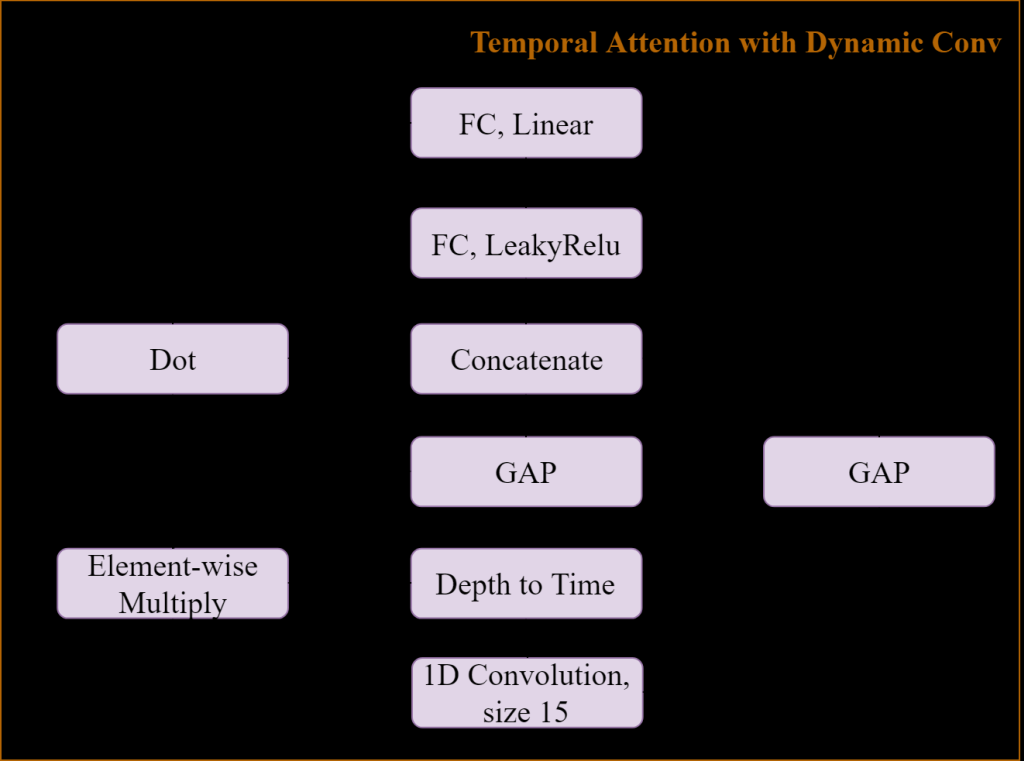
| 科學突破性 | 本技術提出的單通道的端到端輕量化音樂源分離模型,成功地結合影像語義分割中的傑出方法,減少編碼層數,使得現在只需要過去模型不到10的參數量並獲得更好的分離效果。透過利用深度與時間的相互轉換來加速運算,對於硬體資源受限的環境更加友善。時間注意力機制與動態卷積核的引入,再結合本次提出的接受域不變之解碼器 |
||
| 產業應用性 | 既有的音源分離模型已有一定效果,但其模型複雜,在設備運算效能受限的狀態下難以利用於實時應用。本技術雖應用於歌曲人聲音樂分離,但目的是推廣到各種現實上的實時應用,如背景噪音消除、真實人聲對話擷取等。故此專注於較短時間的輸入,亦即低延遲的狀態下,改良現有深度學習模型,以期達成減少參數量,提升運算速度,改 |
||
| 關鍵字 | 音源分離 Wave-U 網路 空洞空間池化金字塔 空洞卷積 編碼器-解碼器 時間注意力 動態卷積核 接受域不變的解碼器 語義分割 深度可分離卷積 | ||
- 聯絡人
- 劉家瑋
- 電子信箱
- holidaypanic@hotmail.com
其他人也看了