



| Technical Name | A Novel Method for Detecting New Anomaly (DNA) of HTTP Service | ||
|---|---|---|---|
| Project Operator | National Chung Hsing University | ||
| Project Host | 廖宜恩 | ||
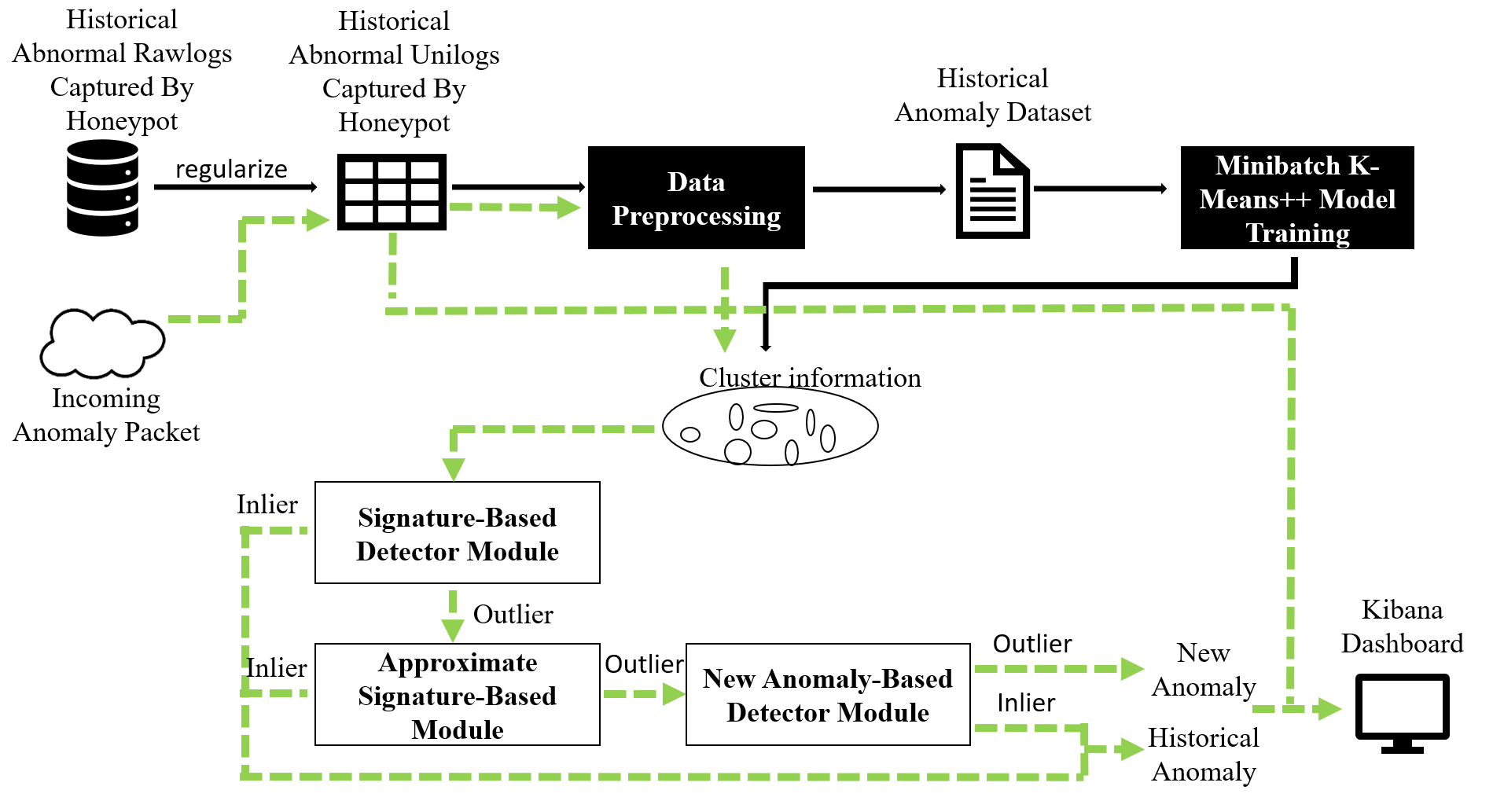
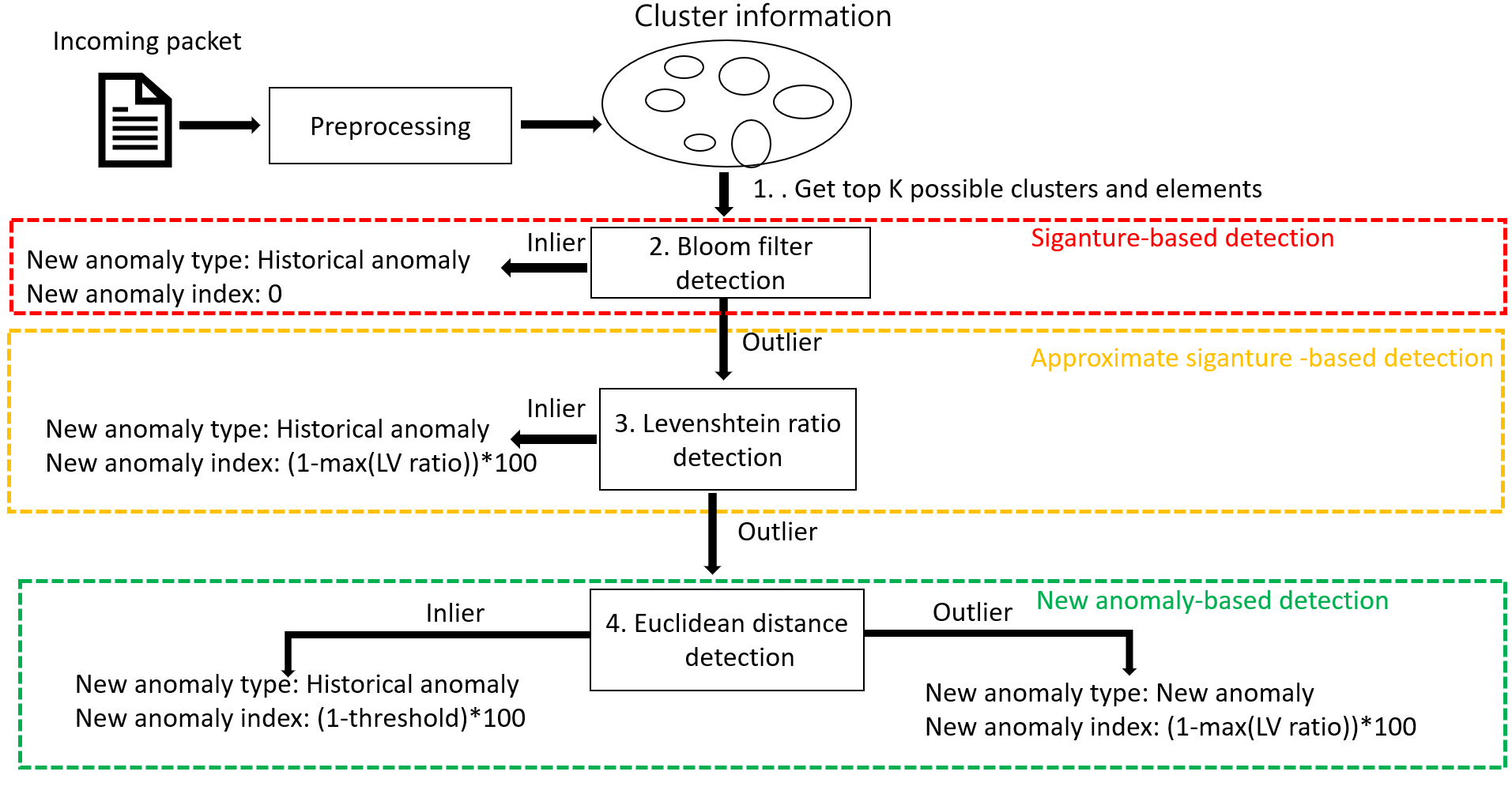
| Summary | The proposed method (aka DNA of HTTP) can identify the HTTP service packet newly captured by the Glastopf honeypot and distinguish whether it is a new abnormal type. The main technical steps of DNA of HTTP are as follows: |
||
| Scientific Breakthrough | The proposed DNA of HTTP system combines the advantages of three types of detection methods including signature-based, approximate signature-based, and new anomaly-based methods. It can learn abnormal traffic captured by honeypots with unlabeled, complex patterns, and even every imbalanced data. It can identify new anomalies accurately and reduce the time required for security personnels to inspect the log. |
||
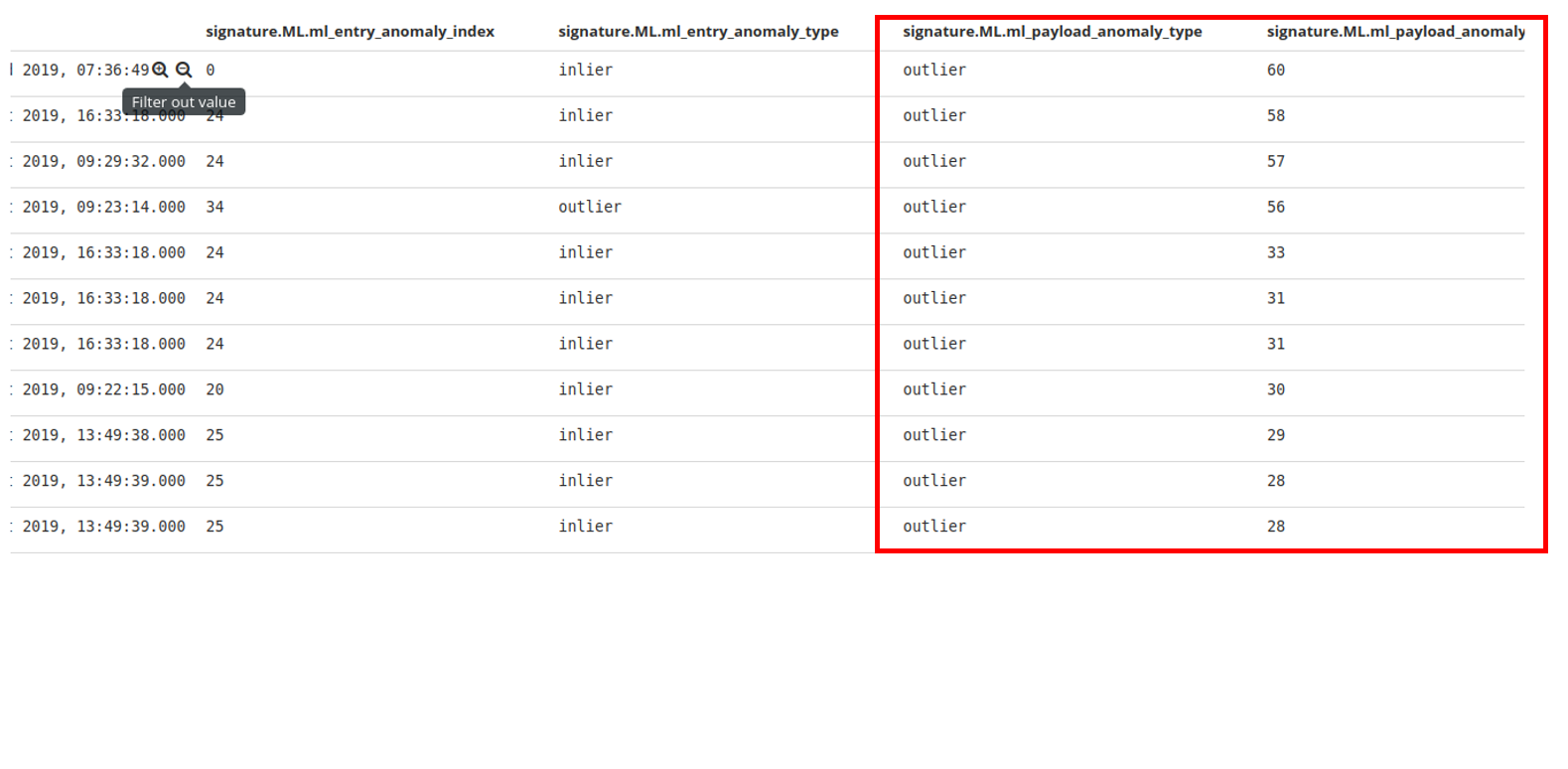
| Industrial Applicability | This system aims at establishing a semi-supervised new anomaly detection system for the honeypot deployed by information security research institutions. The proposed methods can automatically and quickly identify whether a packet captured by the honeypot is a new anomaly and compute a new anomaly index to significantly reduce the time required for analysts to inspect the log. |
||
| Keyword | New anomaly detection system Intrusion detection system Anomaly detection Honeypot Industrial control system HTTP Semi-supervised Signature-based Approximate signature-based Anomaly-based | ||
- brucewarm26@gmail.com
other people also saw