



| Technical Name | 神農 GPT: A Scalable Agricultural Knowledge Retrieval and Answering System | ||
|---|---|---|---|
| Project Operator | National Chung Hsing University | ||
| Project Host | 吳俊霖 | ||
| Summary | 神農GPT is a knowledge Q&A system integrating Document Retrieval, Extractive Reading, and Generative Language Models for Fact-Retrieval. It prioritizes accuracy in agricultural queries, counteracting the Hallucinations seen in other generative models. By relying on its in-built knowledge base, it assures trustworthy responses. The system is tailored for agriculture, with models trained using Question Generation, agricultural literature, the Inverse Cloze Task, and Pseudo Question Learning, optimizing its reading comprehension of agricultural texts. Unlike purely generative systems, it retrieves, extracts, then consolidates answers, cutting costs and boosting efficiency, and cites knowledge sources. |
||
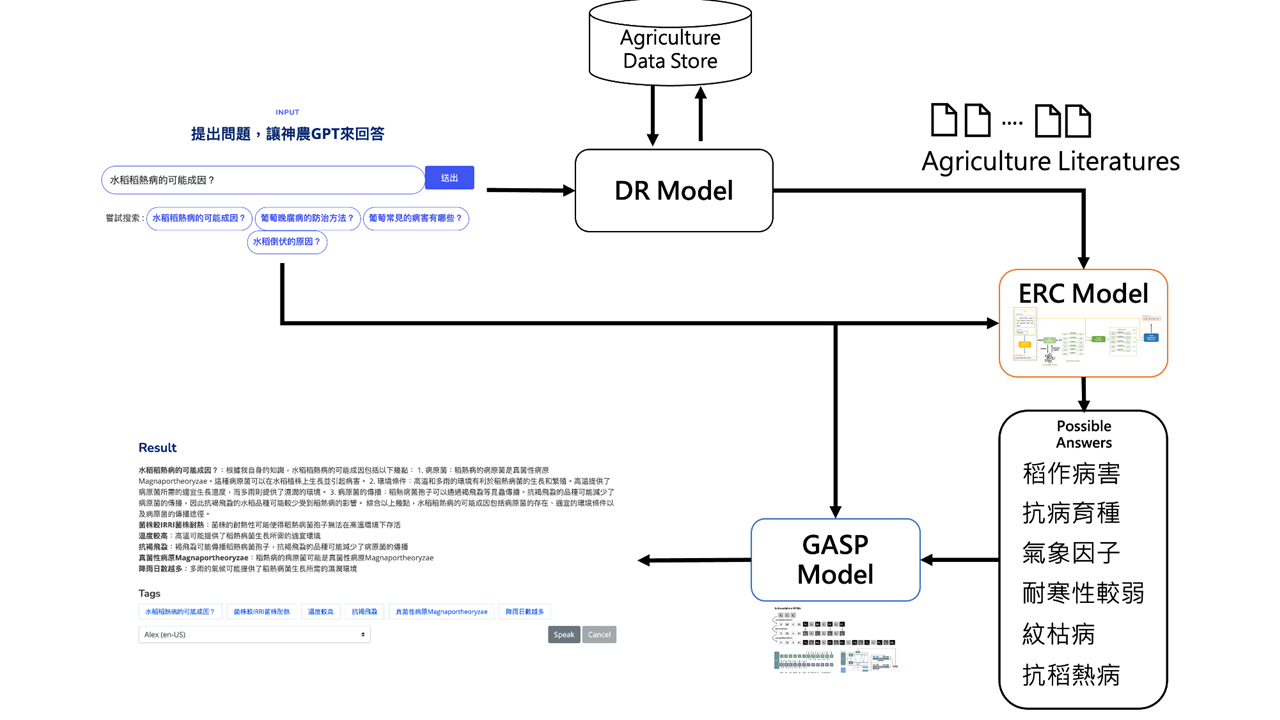
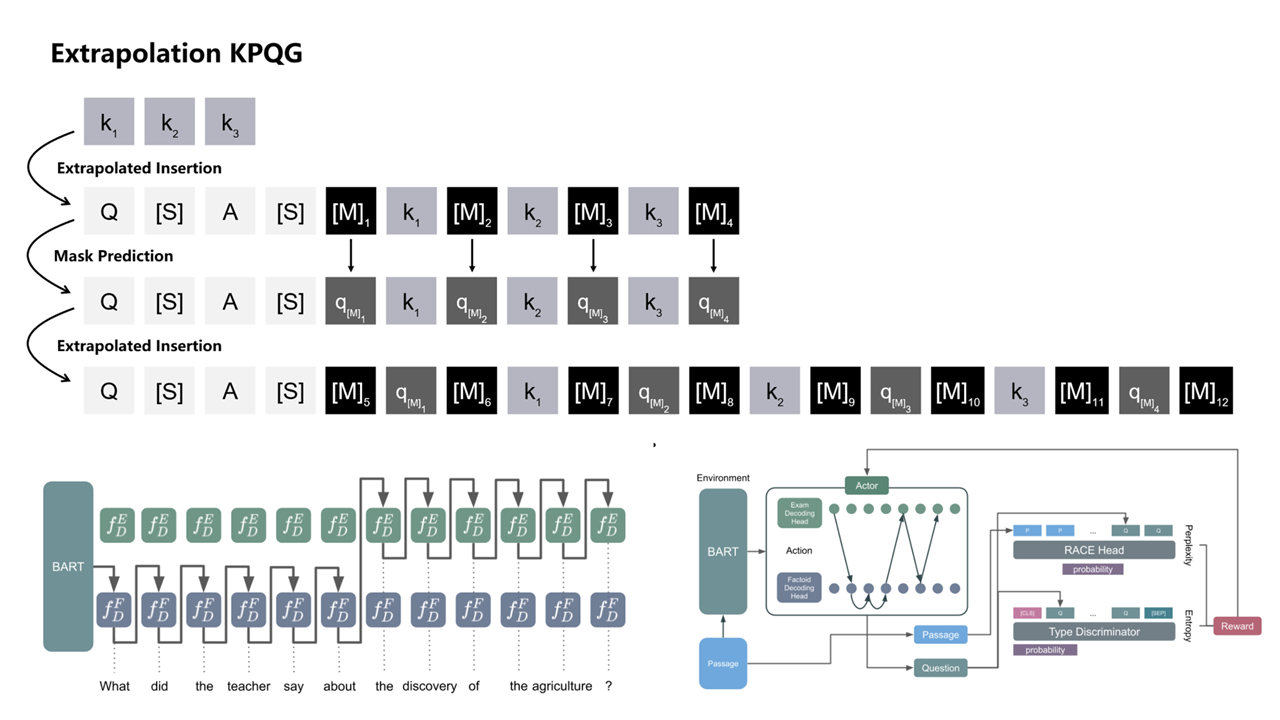
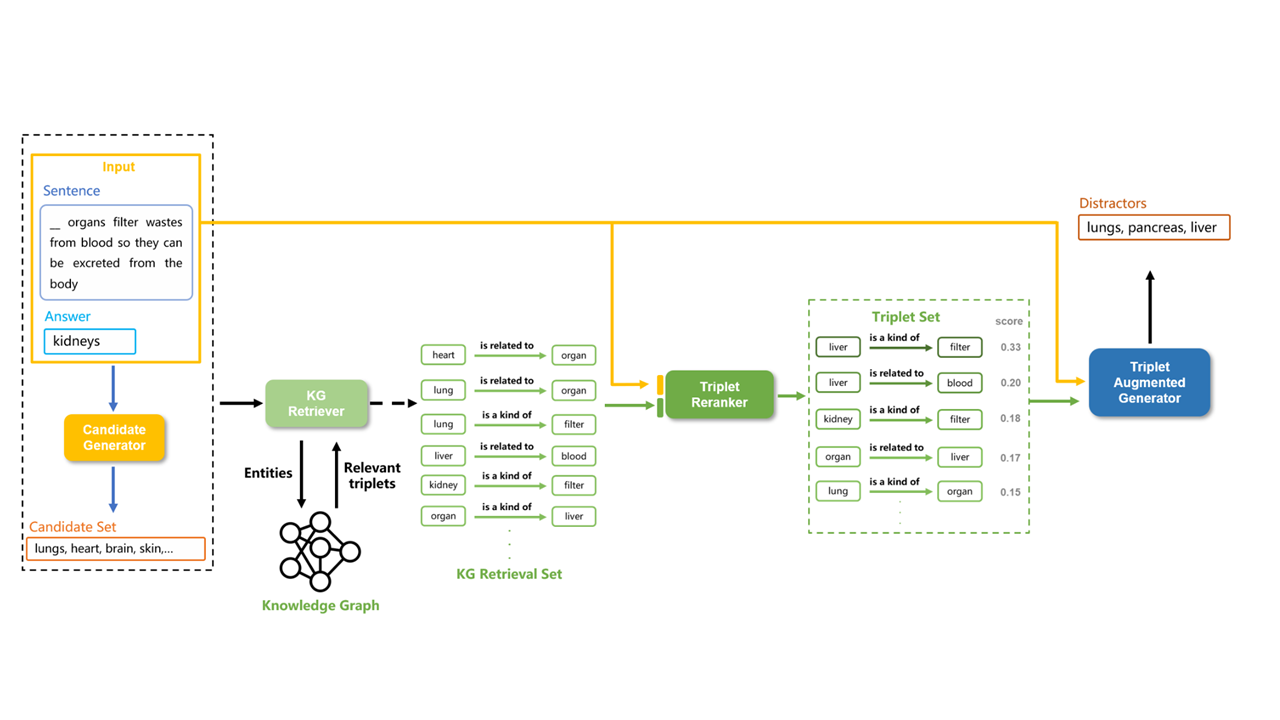
| Scientific Breakthrough | 神農GPT is built on the Extractive Reading Comprehension Model, taking text and a question as inputs to yield potential answers. While existing models aren't tailored for agricultural content, 神農GPT uses question generation for data augmentation in training. We collaborated with agricultural experts for answer annotations, compiling a rich agricultural Q&A dataset. This refined our model, optimized for agricultural contexts. Distractor generation techniques further enhanced its comprehension capability. Our methods were recognized in EMNLP Findings 2022 and ACL Findings 2023, leading natural language processing conferences. |
||
| Industrial Applicability | 神農 GPT is a user-friendly tool for farmers and experts, aiding agricultural knowledge retrieval. Its scalable architecture means as we add more literature (currently 13,000+ pieces), there's no retraining needed, enhancing its knowledge reservoir. With more content, the system's response quality will grow. The system's design, rooted in retrieval and reading comprehension, can be tailored for various fields, like biomedicine or humanities, making it versatile for diverse Q&A applications. |
||
| Keyword | sparsity application | ||
- Contact
- Jiunn-Lin Wu
- jlwu@nchu.edu.tw
other people also saw