



| Technical Name | Application of natural language technology to build AI automation to manage infectious disease pathogen thematic database | ||
|---|---|---|---|
| Project Operator | National Health Research Institutes | ||
| Project Host | 鄒小蕙 | ||
| Summary | Using natural language technology for word tokenization, extracting key data, and searching the law of data appearance, the data, i.e., strain names, antibiotic names, antibiotic susceptibility, and drug resistance, are compiled. This technology can automatically standardize the data format, so that the data meets the needs of professional fields and can be in line with international standards. This database can enrich the domestic research on drug resistance of infectious diseases. |
||
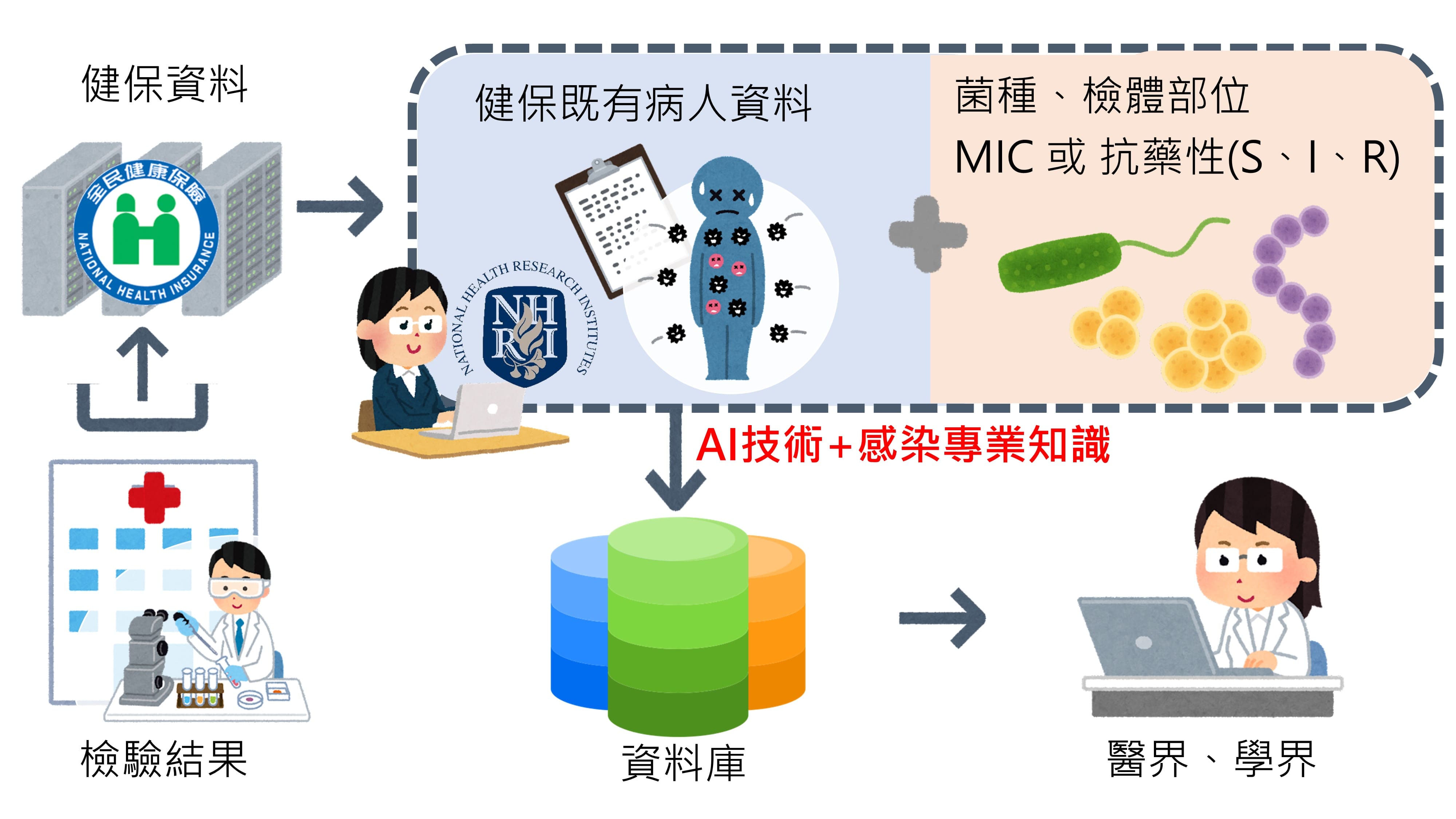
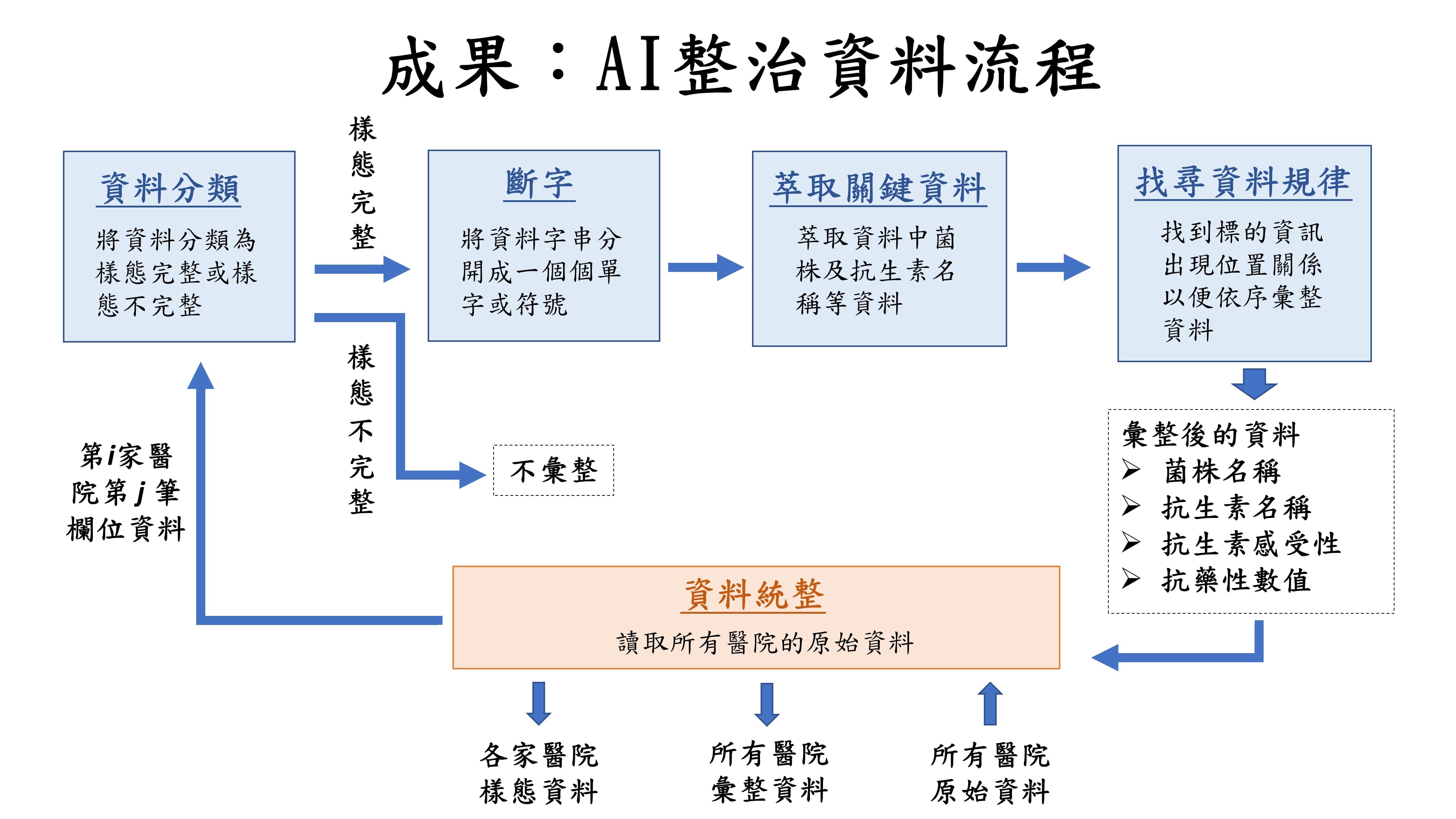
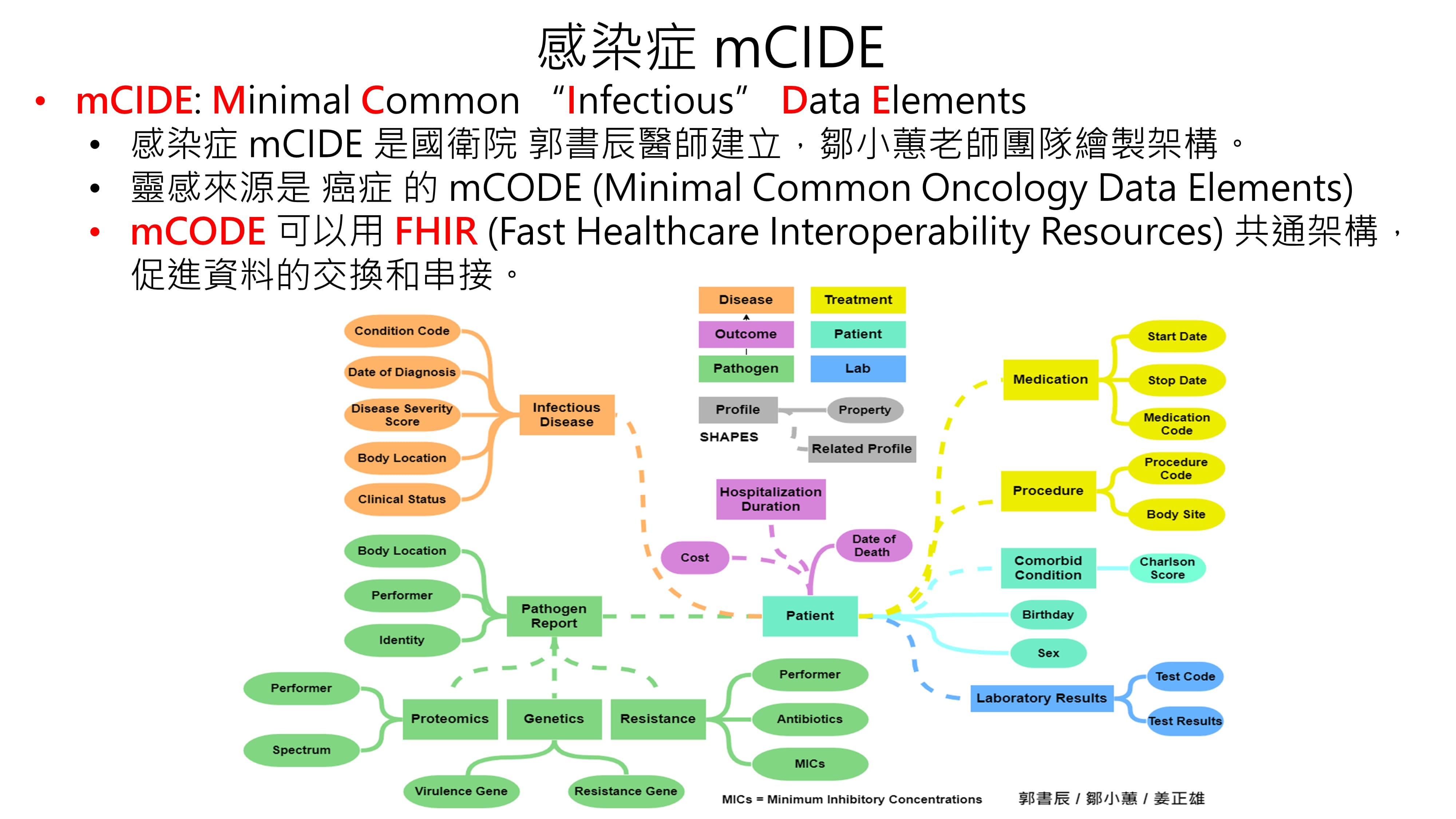
| Scientific Breakthrough | We use "Regular Expression" to tokenize words and extract the essential data from the uploaded data, and also establish a procedure for finding the law of data appearance. This procedure can accurately extract the strain name, antibiotic name, antibiotic susceptibility and resistance values. Our team also created a new column of infectious disease data format: infectious disease mCIDE (Minimal Common “Infectious” Data Elements). |
||
| Industrial Applicability | Our team cooperates with National Health Insurance Administration to improve the consistency and completeness of the infectious disease pathogen data uploaded by the hospitals. Apply natural language technology to develop AI automatic remediation procedures for pathogen data. Use the procedures to compile data to make standardized data meet the needs of professional fields. This pathogen-themed database can enrich domestic research on infectious diseases and drug resistance. |
||
| Keyword | Pathogens thematic databases, natural language processing regular expressions word tokenization the law of data appearance health big data drug resistance databases data governance and data classification | ||
- Contact
- Fang-Jing Lee
- fjlee@nhri.edu.tw
other people also saw