



| Technical Name | Zero-Shot Unseen Speaker Voice Synthesis | ||
|---|---|---|---|
| Project Operator | National Central University | ||
| Project Host | 王家慶 | ||
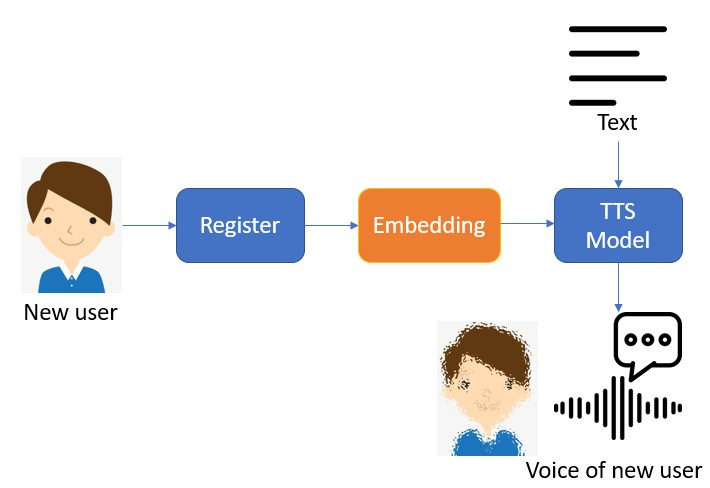
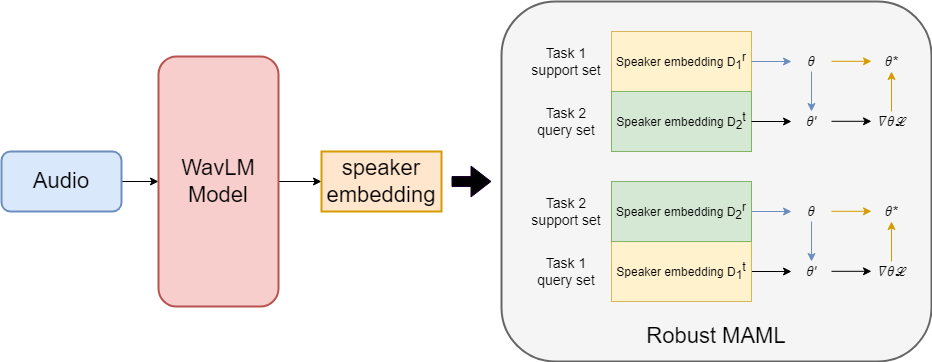
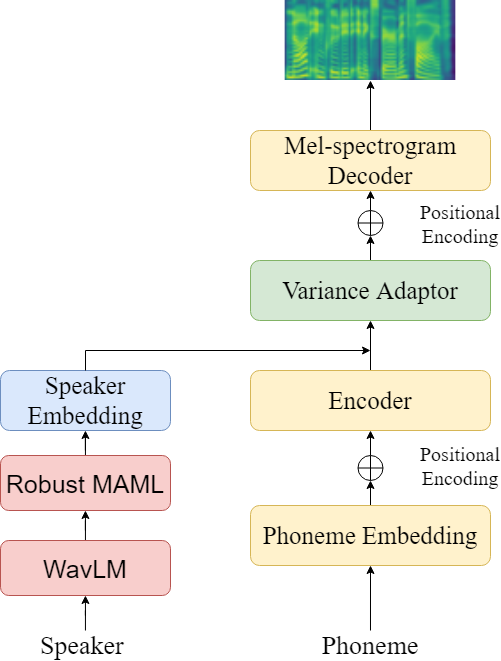
| Summary | We use a pre-trained speaker encoder to obtain semantic information in speech,train a WavLM-based speaker encoder. We obtain domain-independent speaker information through Robust MAML for domain generalization training. So, the domain-independent speaker information can be applied to any untrained speaker. The effect of this speaker feature is transferred to the speech synthesis model, thereby achieving zero-resource speech synthesis results. |
||
| Scientific Breakthrough | In order to be able to fit the naturalnesssimilarity of the synthesized speech of zero-resource unregistered speakers in the speech conversion model, We use the Robust MAML training method to obtain the speaker features of domain generalization, so that it can overcome the problem of the domain gap between the unregistered datathe registered data, effectively retain the domain-independent speaker features of the target speakers, use this feature to the training of the speech synthesis model,improve the naturalnesssimilarity of unregistered speakers in the original model. |
||
| Industrial Applicability | The zero-resource speech synthesis system has a wide range of application scenarios,can be used in various situations. For example, through this technology, the voice actor only needs to dub a small number of sentences when dubbing,the rest of the sentences can be generated by the machine itself. The virtual characters can also be created. In addition, depending on the choice of semantic encoder, the technology can also be applied to data augmentationspeech conversion. |
||
| Keyword | speaker encoding domain generalization meta learning speech synthesis voice conversion voice translation data augmentation transfer learning forward-looking voice technology deep learning | ||
- Contact
- Jia-Ching Wang
- jiacwang@gmail.com
other people also saw