



prev
next
| 技術名稱 | 輕量化深層類神經網路MobileNet與APP架構:人工電子耳及助聽器降噪與提升聆聽效益的大趨勢 | ||
|---|---|---|---|
| 計畫單位 | 振興醫療財團法人振興醫院 | ||
| 計畫主持人 | 力博宏 | ||
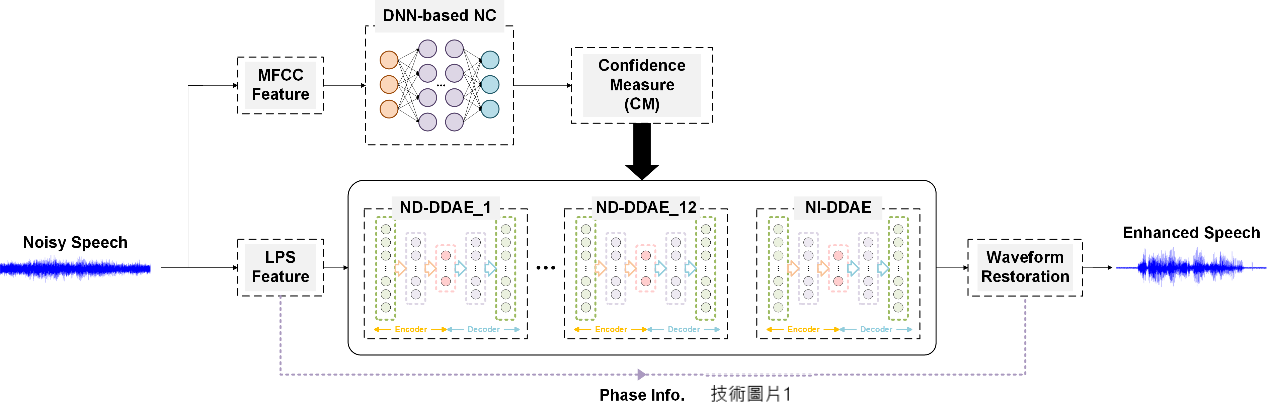
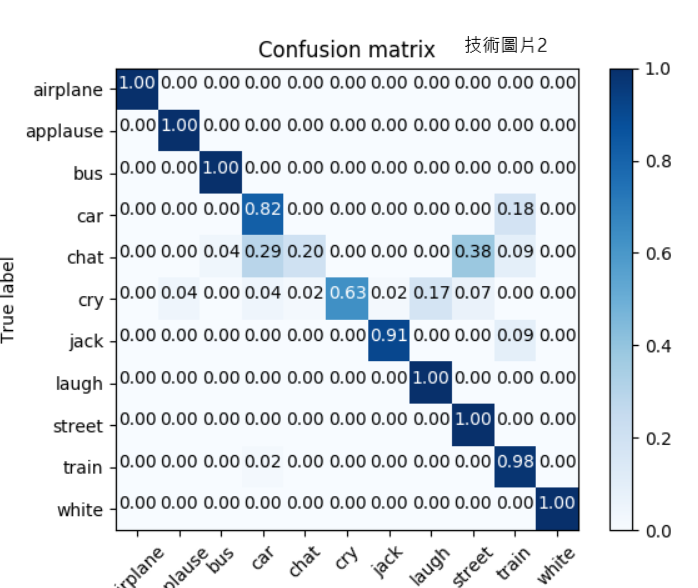
| 技術簡介 | 整體降噪系統架構圖如技術圖片一所示,主要分為兩種神經網路類型,第一個神經網路模型的類別為噪音分類器(NC),第二個神經網路模型的類別為深度除噪自動編碼器(DDAE),兩種神經網路皆使用輕量化的深度學習網路架構,可放置在嵌入式系統上運行。噪音分類器的功能主要是用來區分語音中所夾帶的噪音種類,透過這個神經網路模型,就能預先訓練11種日常常見的噪音,包含飛機客艙聲、公車內行駛聲、火車內行駛聲、小客車內行駛聲、路上車流聲、施工鑽地聲、群眾拍手聲、群眾聊天聲、群眾笑聲、小孩哭聲、白噪音。未來若需要對更多的噪音類別進行分類也能夠透過收集新的噪音資料並重新訓練神經網路參數來達成。此外一個系統中總共包含12個深度除噪自動編碼器,其中的11個噪音相關(Noise Dependent, ND)深度除噪自動編碼器對應到各自的噪音類別,能夠針對某一種噪音環境達到降噪的功能,剩餘的一個非噪音相關(Noise Independent, NI)深度除噪自動編碼器則是對未包含在11種噪音類別的噪音進行降噪,降噪效果比前11個深度除噪自動編碼器效果差,但是能夠適應比較多種噪音的情況。 |
||
| 科學突破性 | 在降噪神經網路系統中,先經過噪音分類器辨識當前場景,依照分類器結果選擇相對應的深度除噪自動編碼器能使降噪效果更佳。同時為了達到輕量化的效果,並且能將神經網路放在嵌入式系統上,我們一改過去的全連接架構,而使用卷積神經網路架構完成兩種類型之神經網路。 |
||
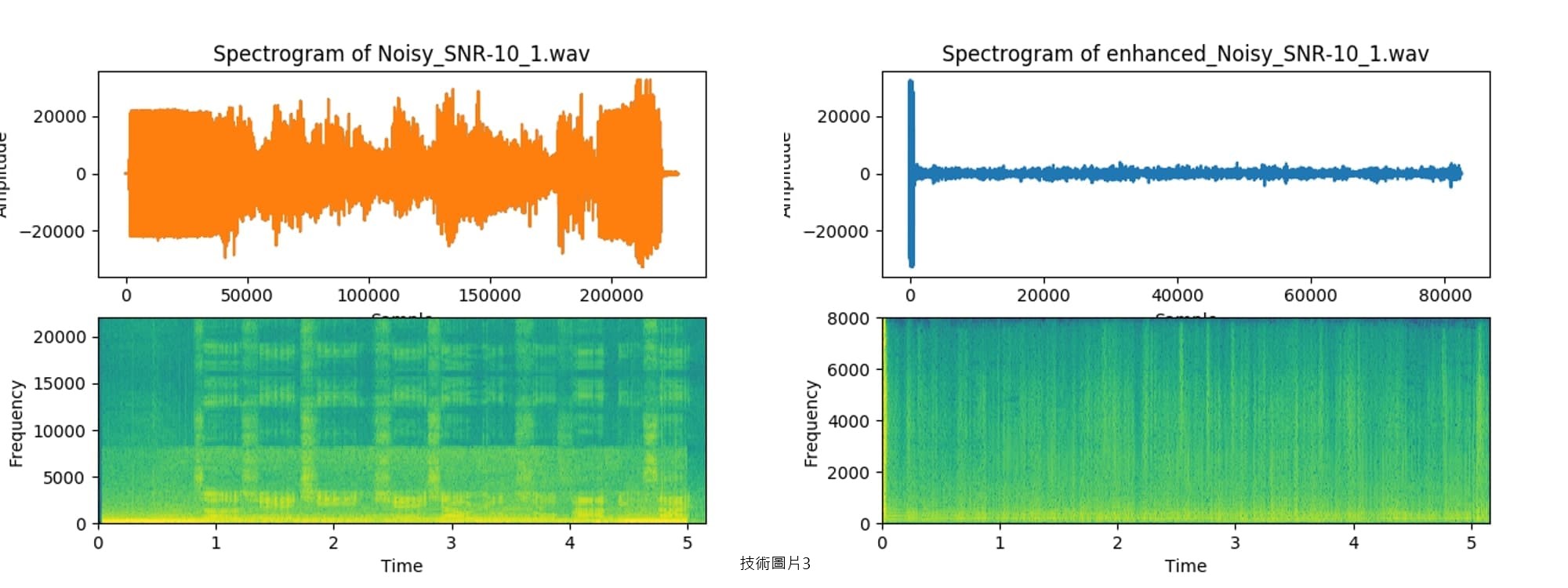
| 產業應用性 | 本團隊設計的 NC+DDAE 模型期望未來可結合電子耳、助聽器等助聽輔具,此系統主要功能是讓使用者在噪音環境下能聽到更加清晰之語音,以提升噪音環境下之語音聽辨能力。在朝向積體電路設計前,本團隊目前已先將其系統實踐於 Android 手機中,此系統將做為前端信號處理單元,將噪音去除後再傳至助聽輔具中。 |
||
| 關鍵字 | 助聽器 電子耳 人工智慧 深度學習 卷積神經網路 輕量化深度神經網路 噪音分類 噪音消除 嵌入式應用 手機應用程式 | ||
- 聯絡人
- 羅雅君
- 電子信箱
- hearingchgh@gmail.com
其他人也看了
prev
next