




| Technical Name | See-through-Text Grouping for Referring Image Segmentation | ||
|---|---|---|---|
| Project Operator | Institute of Information Science, Academia Sinica | ||
| Project Host | 劉庭祿 | ||
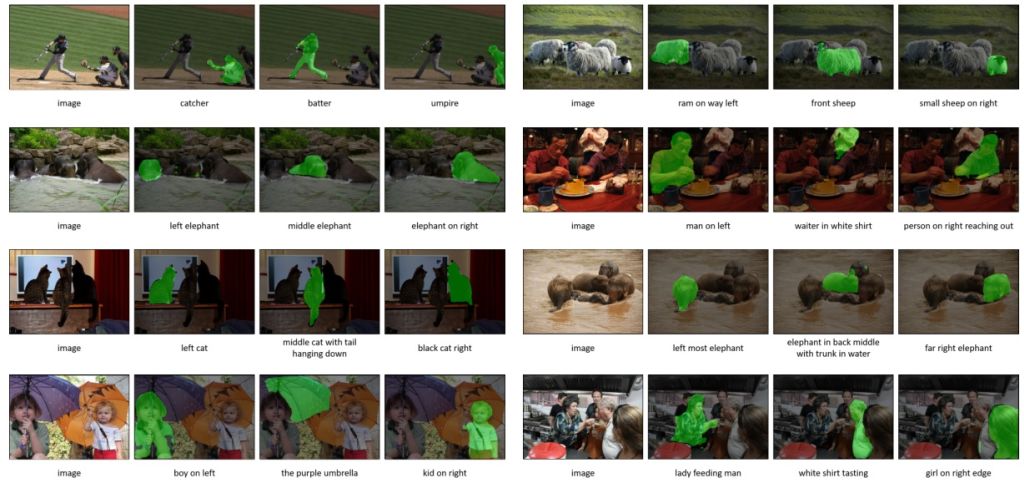
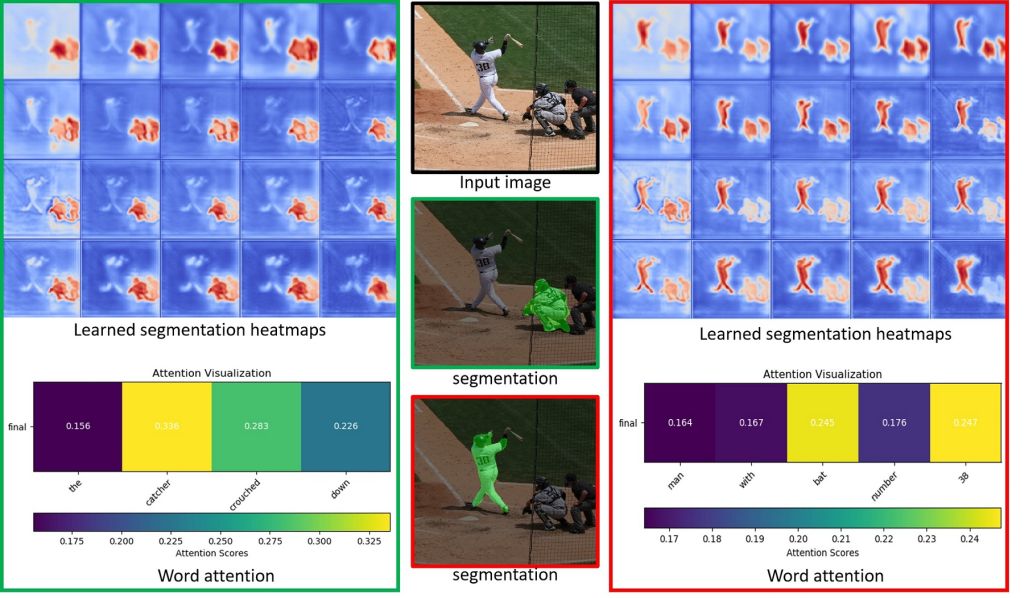
| Summary | We propose an iterative learning scheme to tackle the referring image segmentation. In each iteration starting from a given a referring expression, the scheme learns to predict its relevance to each pixelderives a see-through-text embedding pixel-wise heatmap. Then, a ConvRNN refines the heatmap for altering the referring expression to start the next iteration. |
||
| Scientific Breakthrough | The technique iteratively updates the language expression, generatesrefines the heatmap to tackle the referring image segmentation. Our model is end-to-end trainableshows the SOTA performance on four datasets without using an object detectoran attribute predictor as the existing models. This technique is easy to trainprovides additional attention-based referring representation. |
||
| Industrial Applicability | The multi-modal analysis is one of the main trends in current research. The referring image segmentation addressed by our technique is a cross-modal application which associates computer visionnatural language processing. The multi-modal representation embedding method in this technique can be used as a template for the industry to develop multimedia applications on a combination of visual an |
||
| Keyword | Computer Vision Deep Learning Convolutional Neural Network Convolutional-Recurrent Neural Network Image Segmentation Natural Language Referring Segmentation Embedding Attention Referring Expression | ||
- dj_chen_tw@yahoo.com.tw
other people also saw